
机器学习class_2
机器学习任务攻略
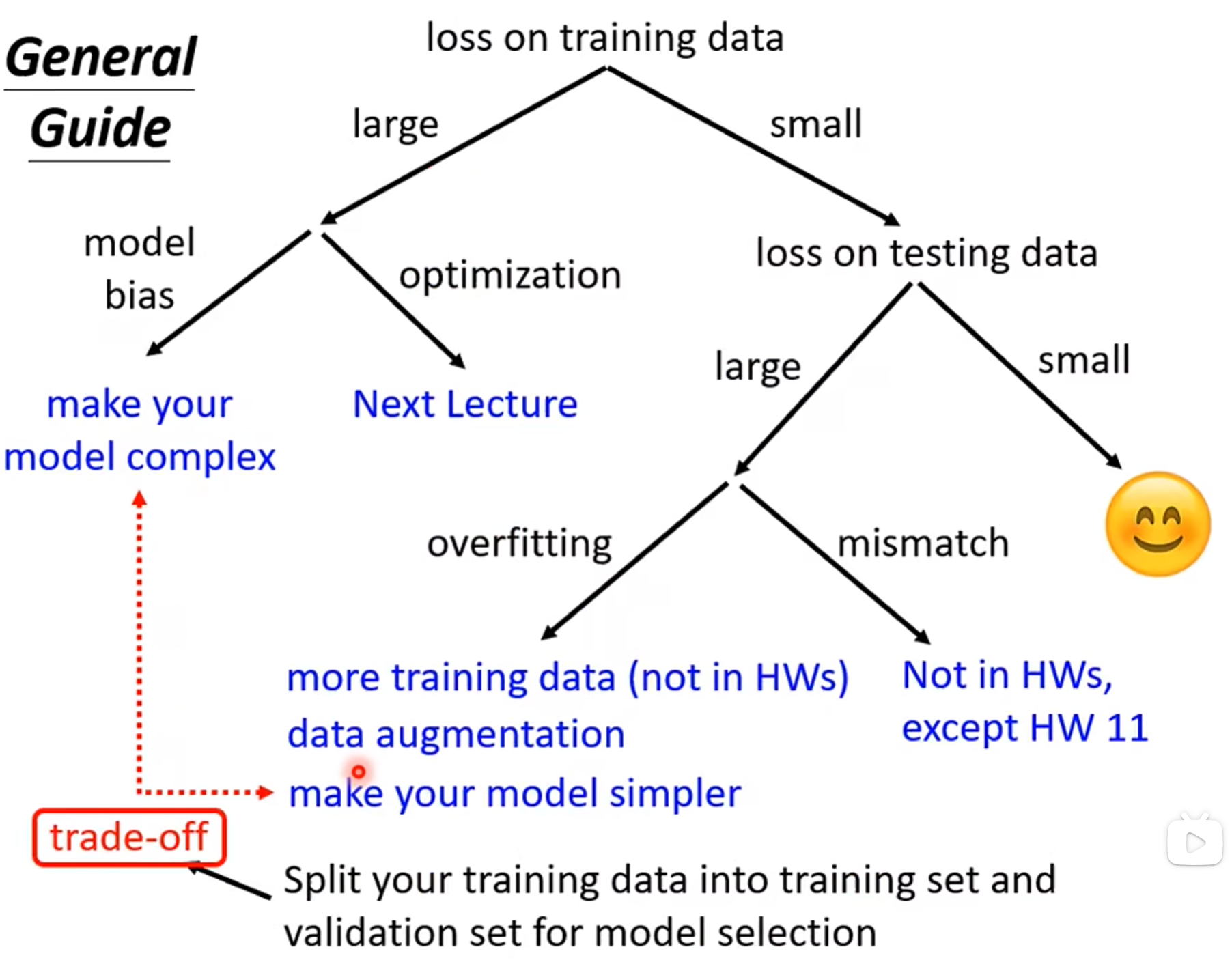
Optimization
local minima or saddle point ?
站在更高的维度,或许 local minima 只是 saddle point
怎么解决呢?
Batch and Momentum
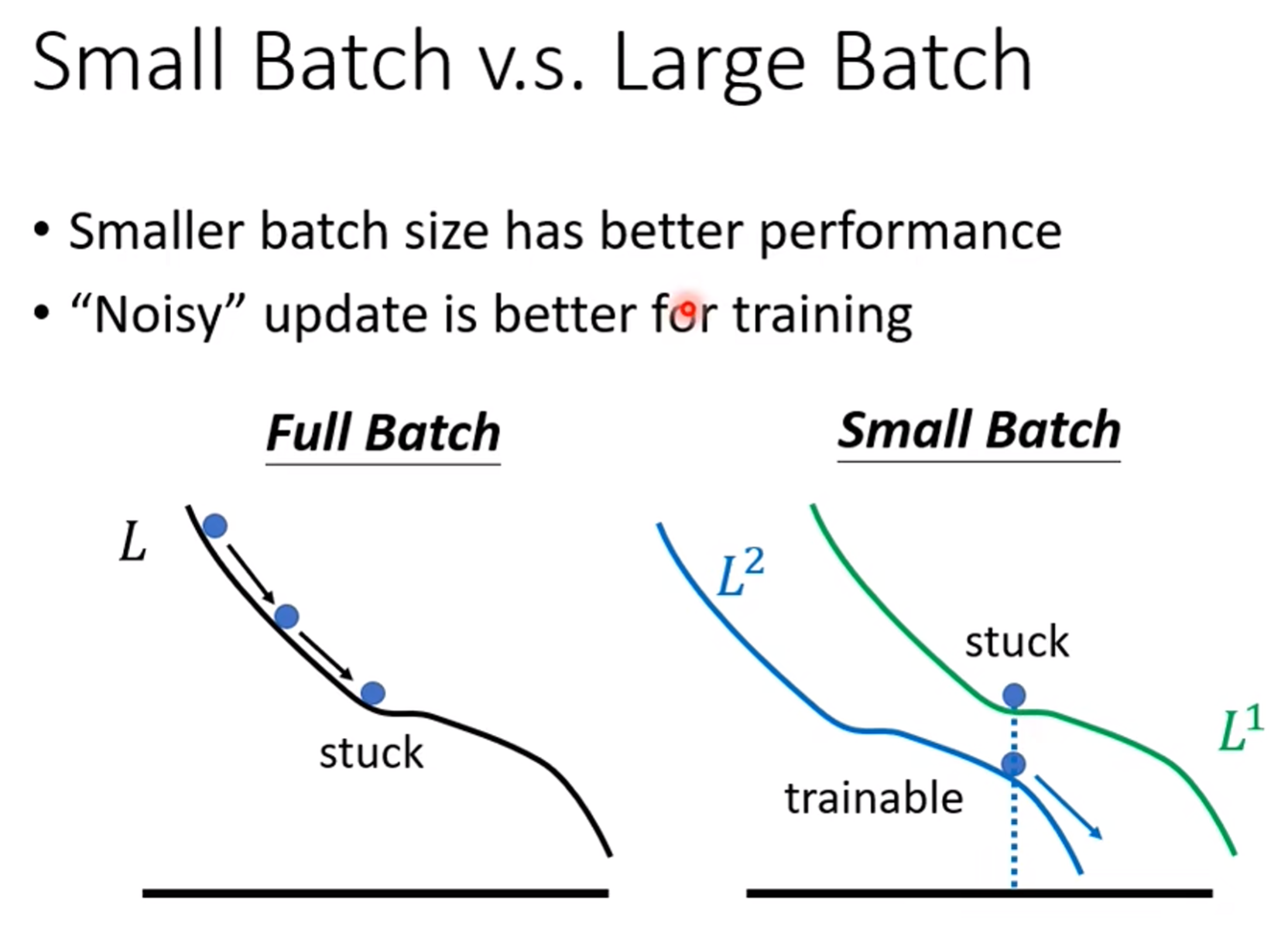
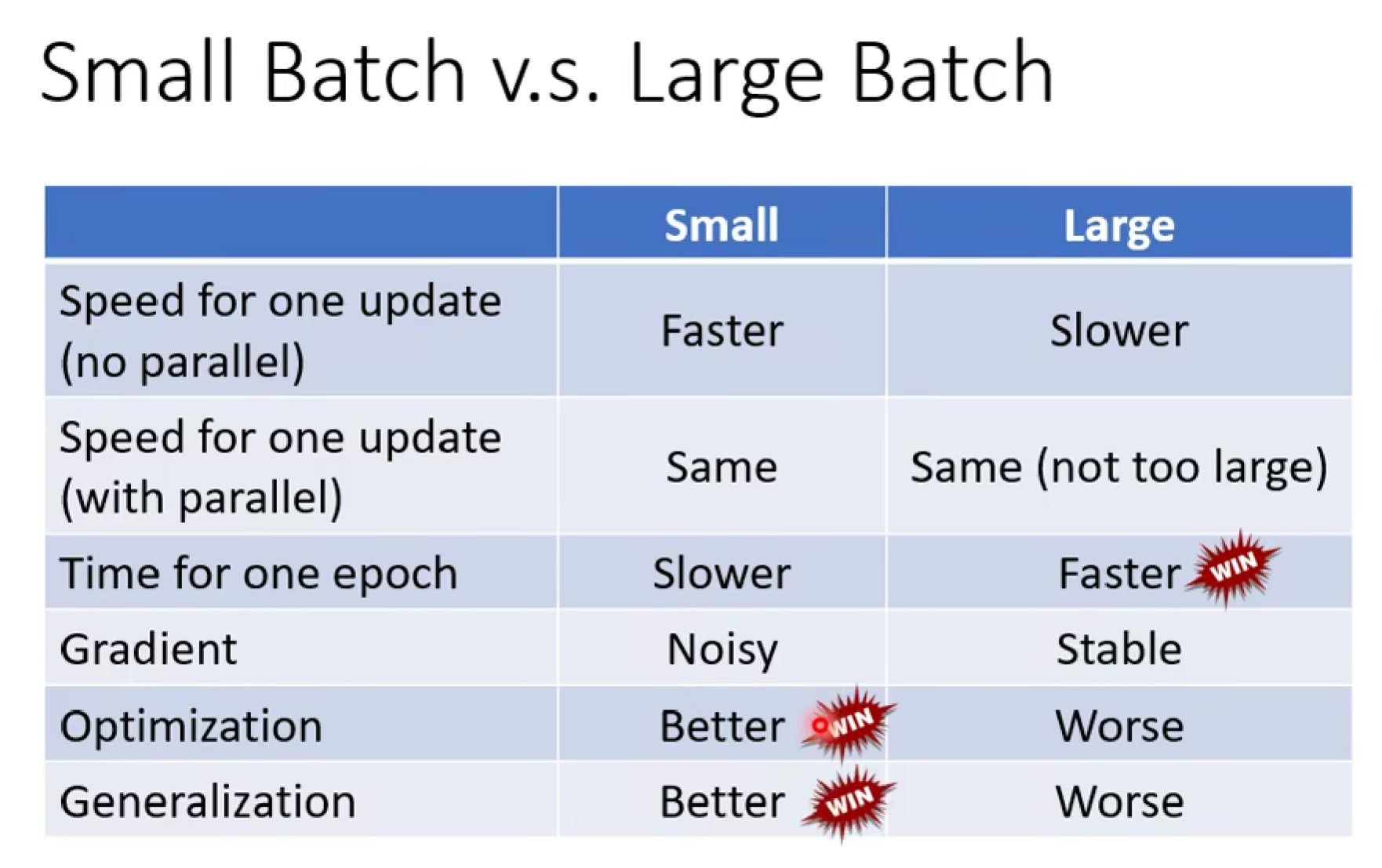
Large Batch vs Small Batch
Large Batch:冷却长,伤害高
Small Batch:冷却短,伤害低
但是由于gpu能做并行计算,large batch时间可以与small batch时间差不多,这样1个epoch时间large batch反而短很多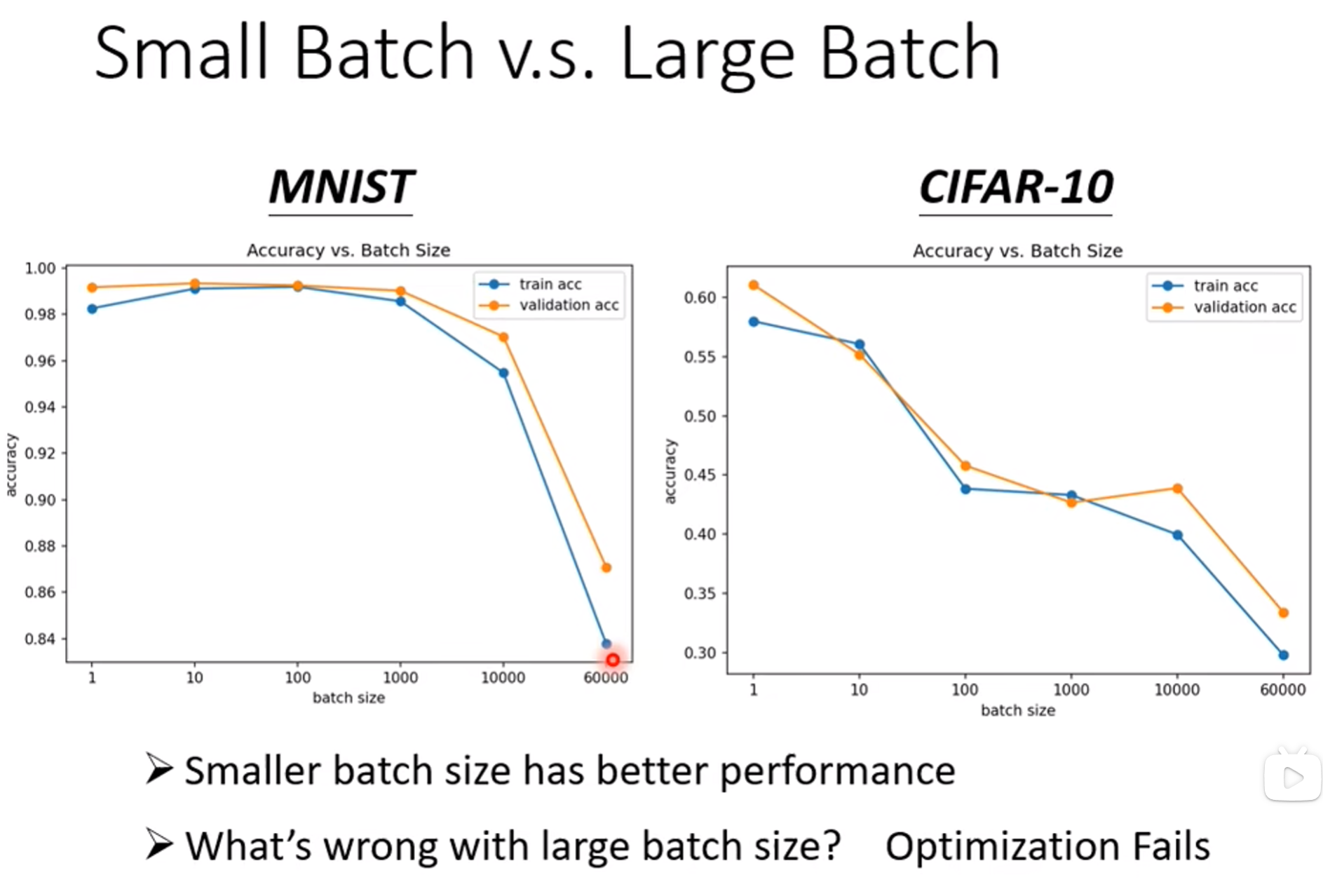
Momentum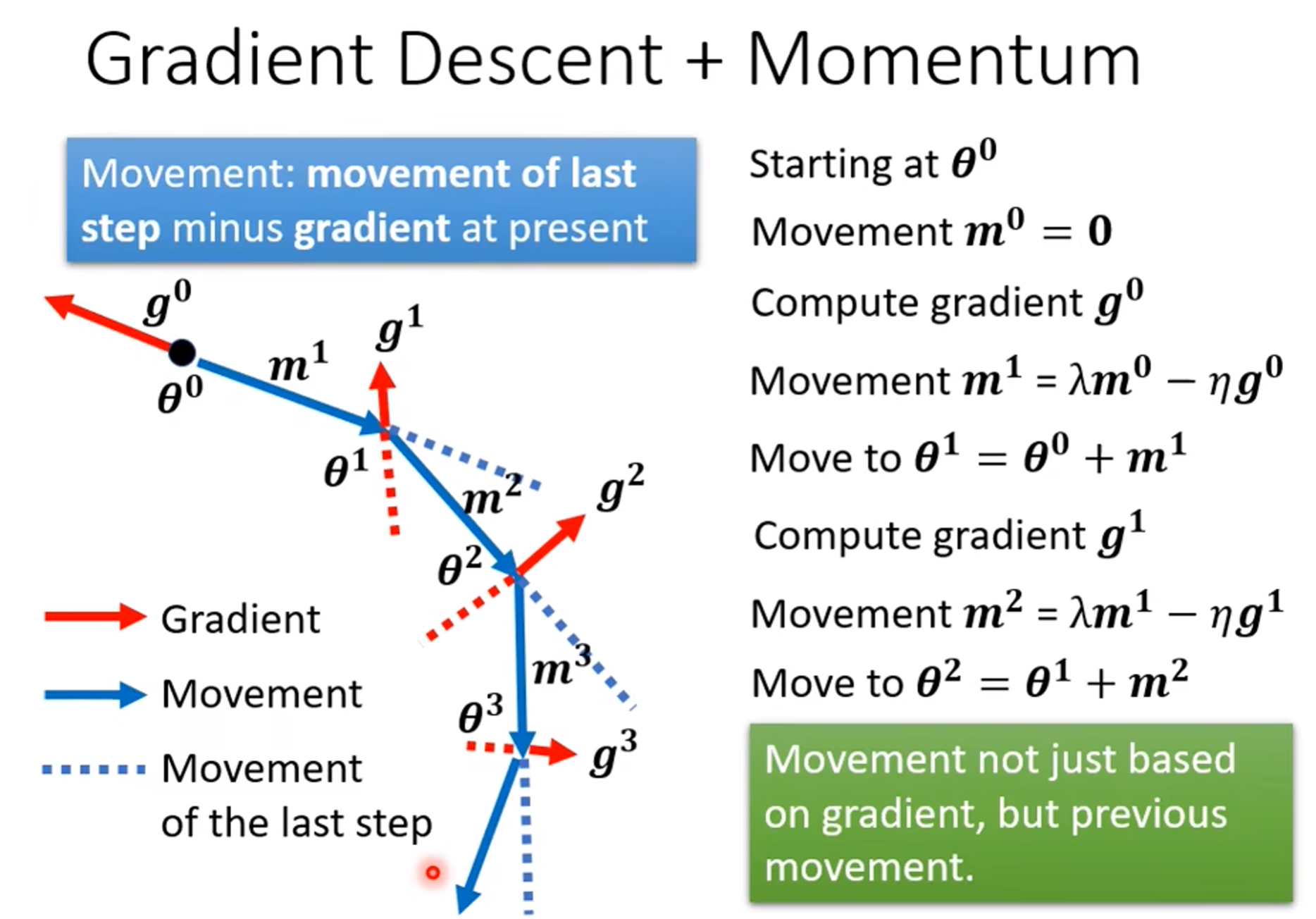
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Bin's blog!