
数据结构13-堆排序
堆排序
动机
直接选择排序低效原因:每次找最大元素需花费O(n)时间,涉及大量重复比较
能否借助树形结构,减少元素的重复比较次数
锦标赛排序
利用胜者树保存了前面比较的结果,下一次选取最大元素时直接利用前面比较的结果,从而大幅减少关键词比较次数
堆的概念及基本操作
最大堆(大根堆):一颗完全二叉树,其中任意结点的关键词大于等于它的两个孩子的关键词
最小堆(小根堆):一颗完全二叉树,其中任意结点的关键词小于等于它的两个孩子的关键词
回顾:完全二叉树的顺序存储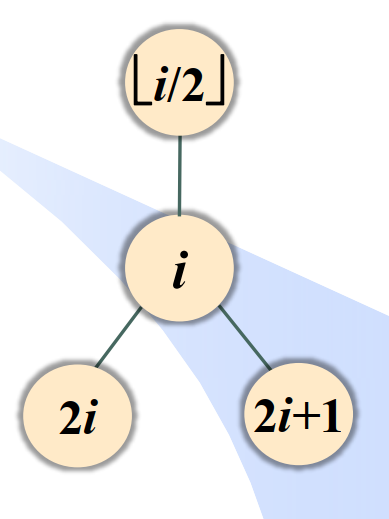
故顺序存储
堆的两个基本操作
上浮操作
当大根堆的元素值R[i]变大时,该结点可能会上浮
1 | void ShiftUp(int R[],int n,int i) |
下沉操作
1 | 当大根堆的元素值R[i]变小时,该结点可能会下沉 |
初始建堆
自顶向下
- 建立T的左子堆
- 建立T的右子堆
- 结点T下沉
自底向上
- 从最后一个非叶节点开始,依次建立以每个非叶节点为根的子堆
1 | void BuildHeap(int R[],int n) |
初始建堆算法的时间复杂度:取决于各结点高度之和
各节点高度之和小于n,算法最坏情况时间复杂度O(n)
堆排序算法
- 建堆
- for(int i=n;i>1;i–)
{
R[1]<->R[i];
下沉R[1]使R[1]…R[i-1]重新建堆
}
时间复杂度O(nlogn)
不稳定1
2
3
4
5
6
7
8
9void HeapSort(int R[],int n)
{
BuildHeap(R,n);
for(int i=n;i>1;i--)
{
swap(R[1],R[i]);
ShiftDown(R,i-1,1);
}
}
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Bin's blog!